
When conversing with large models like ChatGPT, sometimes it feels like talking to a fish with a seven-second memory due to the token length limitations it can handle. Once the conversation exceeds a certain number of tokens, it forgets previous dialogue. Indeed, current large language models (LLMs) can only retain a limited context during inference. For example, LLama2 can only process a 4K context, which not only prevents it from remembering content beyond the most recent 4K tokens, but also causes it to stop generating text once it reaches the 4K limit.
If large models could function like humans—remembering past conversations for extended periods and even doing so better than the human brain—then we would unlock a broader range of applications, allowing AI to do more. Therefore, the ideal AI conversation assistant should not be limited by output length and should be able to remember previous conversations.
In multi-turn dialogues and other streaming applications, which are expected to involve long-term interactions, the industry is currently exploring methods to enable large LLMs to process longer contexts.
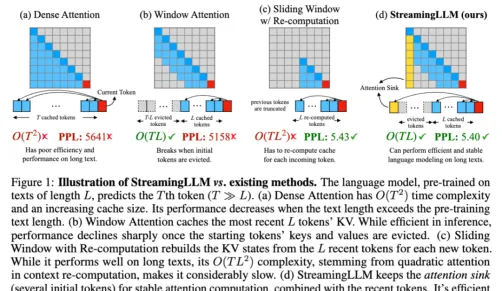
To achieve efficient streaming deployment of LLMs, researchers have proposed the Streaming LLM framework. The core idea is to retain the most recent tokens and important attention points while discarding unnecessary intermediate tokens. This approach allows LLMs to efficiently process longer contexts, showing great potential in scenarios like multi-turn dialogues.
Now, let's look at some key questions about LLMs:
What does “handling infinite-length input” mean for LLMs?
Processing infinitely long text with an LLM is challenging. Storing all previous key-value (KV) states requires a lot of memory, and the model may struggle to generate text longer than its training sequence length. Streaming LLMs solve this by retaining only the latest tokens and attention clusters, discarding intermediate tokens. This way, the model can generate coherent text from the most recent tokens without resetting the cache, a capability not possible with earlier methods.
Will the context window of LLMs increase?
No. The context window remains unchanged. It only retains the most recent tokens and attention, discarding intermediate tokens. This means the model can only process the most recent tokens. The context window is still limited by the initial pre-training. For example, if Llama-2 uses a 4096-context window during pre-training, the maximum cache size for Streaming LLM on Llama-2 is still 4096.
Can long texts (like a book) be inputted into Streaming LLM for summarization?
While long texts can be inputted, the model can only recognize the most recent tokens. So, if you input a book, the Streaming LLM might only summarize the last few paragraphs, which may not be deeply meaningful. As emphasized earlier, this solution does not expand the LLM's context window or enhance its long-term memory. The advantage of Streaming LLM lies in its ability to generate smooth text from the most recent tokens without needing to refresh the cache.
What are the ideal use cases for Streaming LLM?
Streaming LLMs are optimized for multi-turn dialogues and other streaming applications. They are well-suited for scenarios where the model needs to run continuously without requiring large memory or relying on past data. A daily assistant based on LLMs is one example. Streaming LLM allows the model to keep running and respond based on the most recent conversation without needing to reset the cache. Earlier methods would either require a cache reset when the conversation exceeds the training length (losing the most recent context) or need to recalculate KV states based on the recent text history, which can be time-consuming.
However, it's important to emphasize that this method does not increase an LLM's memory of prior context; it simply allows it to handle infinite-length input/output. One clear benefit is that when a chatbot generates a long response, you no longer need to input “continue.”
If you want to enhance context memory, we recommend : The context memory feature in LBAI’s system is a powerful tool that remembers your past needs and preferences with each interaction. Whether in finance, content creation, or other fields, LBAI can provide personalized solutions based on historical behavior and requirements.
Key Features and Benefits Examples
Personalized Investment Advice: The context memory feature can record investors' risk tolerance and investment preferences, providing tailored investment advice and risk assessments, improving strategy accuracy.
Smart Fraud Detection: By analyzing user transaction behavior through context memory, LBAI can identify abnormal activities and reduce financial fraud risks.
Customer Relationship Management: The system remembers each client’s specific needs and past inquiries, providing more personalized customer service, enhancing satisfaction and loyalty.
Personalized Content Recommendations: Based on users' reading and viewing history, the system recommends relevant content, increasing user engagement and platform activity.
Intelligent Content Creation Assistance: Context memory can remember creators' styles and themes, offering related materials and inspiration to boost creative efficiency.
Targeted Marketing: By analyzing user interests and behaviors, context memory enables the creation of precise marketing strategies, enhancing ad performance and conversion rates.
Personalized Health Management: Remembers each patient’s medical history, medication records, and lifestyle habits, providing tailored health management and preventive measures.
Intelligent Diagnostic Support: Through context memory, the system analyzes a patient's medical history and symptoms, helping doctors make more accurate diagnoses and treatment recommendations.
LBAI’s context memory feature is not just a technical breakthrough but a commitment to future industry transformations. We aim to help businesses improve efficiency, optimize services, and innovate operational models through intelligent technology. No matter what industry you’re in, LBAI will provide strong support in your work.