For the past six months, our team has been quietly building an internal project codenamed “L1-L2-L3.” Today we’re sharing the philosophy behind it—no implementation details, no IP leakage, just the why and the what.
1. From “Humans Testing AI” to “AI Testing Itself”
Traditional QA looks like this: humans write scripts → humans set assertions → humans read logs → humans make the call.
Our new loop is simpler: AI authors the cases → AI learns the assertions → AI ingests the logs → AI converges on a verdict.
Tests are no longer frozen artifacts; they are a living learning system—sample, feedback, adjust, converge. If that reminds you of model training, you’re spot on.
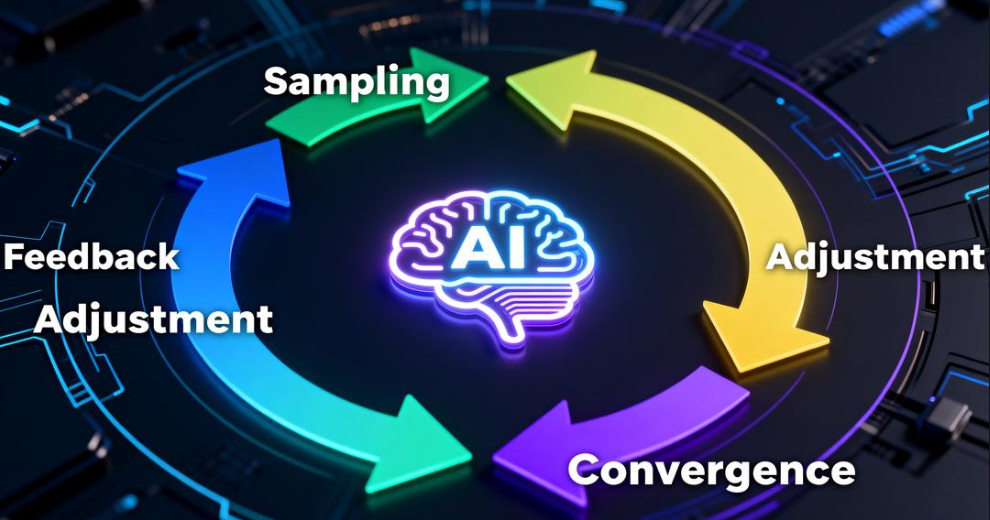
2. Why It Takes GPT-5-Level Intelligence
To pull this off, a model needs simultaneous mastery across three layers:
Structural – reason about code contracts;
Semantic – grasp the intent of the task;
Behavioral – sample adaptively, set thresholds, and know when to stop.
Earlier models wobble when asked to “observe, schedule, and assert” in the same breath. GPT-5 is the first to cross that stability threshold, turning AI from the thing under test into the testing engine.
3. AI-Generated Code Is the Perfect Training Set
Code produced by modern models arrives with uniform structure, complete docstrings, consistent naming, and crisp dependency edges. For a learning-based tester, that translates into high-quality training data: contracts are explicit, semantic assertions are derivable, and the entire codebase sits in one semantic space—dramatically shrinking interpretation error.
4. The Wall Between Dev and QA Is Disappearing
Once AI writes the code, it immediately spins up its own test–learn–converge cycle. By the time tests pass, the model has updated its own worldview. Development and assurance collapse into two intertwined learning phases rather than sequential chores.
5. In One Sentence
L1-L2-L3 ports the model-training feedback loop into the realm of code, letting AI be both examinee and examiner, and upgrading testing from “prove it’s right” to “learn until it’s right.”
We believe this is only the opening act of an AI-native software lifecycle. As more teams bring similar ideas into production, the industry will move to faster, safer releases—written, tested, and hardened by AI itself.

We believe that AI usability is not a one-time leaderboard score, but a systematic, long-horizon engineering process that converges over time. By turning testing into training and folding that training into delivery, LBAI has made its choice. We look forward to working with every partner who shares the same goal: bringing AI products that run, work, and keep getting better to every user, every day.